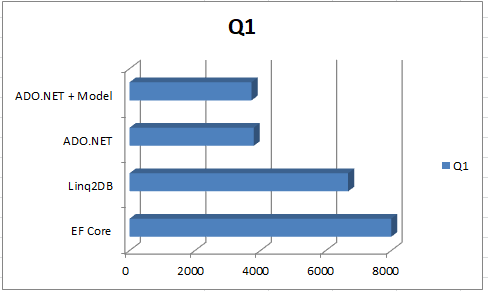
Read about my investigations into database querying performance differences on the Code Project.
The Creative Word
Read about my investigations into database querying performance differences on the Code Project.

There are quite a few blog posts and articles on hooking up the LCD1602 (shown above) to the rPi. But understanding what is going on with all those “magic bits” being set was a mystery, until now! So if you’re looking for an example of how to talk to the LCD1602 with an rPi and using .NET Core to communicate over the I2C bus, and really understand how it works, you should find the article (link below) to answer all your questions.

Excerpt:
Object oriented programming and relational databases create a certain mental model regarding how we think about data and its context–they both are oriented around the idea that context has data. In OOP, a class has fields, thus we think of the class as the context for the data. In an RDBMS, a table has columns and again our thinking is oriented to the idea that the table is the context for the data, the columns. Whether working with fields or record columns, these entities get reduced to native types — strings, integers, date-time structures, etc. At that point, the data has lost all concept as to what context it belongs! Furthermore, thinking about context having data, while technically accurate, can actually be quite the opposite of how we, as human beings, think about data. To us, data is pretty much meaningless without some context in which to understand the data. Strangely, we’ve ignored that important point when creating programming languages and databases — instead, classes and tables, though they might be named for some context, are really nothing more than containers.
Contextual data restores the data’s knowledge of its own context by preserving the information that defines the context. This creates a bidirectional relationship between context and data. The context knows what data it contains and the data knows to what context it belongs. In this article, I explore one approach to creating this bidirectional relationship — a declarative strongly typed relational contextual system using C#. Various points of interest such as data types and context relationships (“has a”, “is a”, “related to”) are explored. Issues with such a system, such as referencing sub-contexts in different physical root-level contexts, are also discussed.
Read the full article on CodeProject.

A hard to read screenshot of HOPE (aka Semantic Computing) is now working on the web under the code name “Temporal Agency” (I love that name!), using:
Features:
This is very snazzy, in my humble opinion. I have a couple demos working:
More to come!
In a previous blog post, I described the high level architecture of microservices
running in a Docker container. This blog post describes (again at a high level) the behind-the-scenes implementation of how a we render the output of a microservice back to the client’s browser. We’ll use the Weather Underground API for acquiring our current weather conditions.
First, let’s start with a semantic address:
public class ST_Address : ISemanticType
{
public string Address1 { get; set; }
public string Address2 { get; set; }
public ST_City City { get; set; }
public ST_State State { get; set; }
public ST_Zip Zip { get; set; }
public ST_Address()
{
City = new ST_City();
State = new ST_State();
Zip = new ST_Zip();
}
Note that there are other semantics involved here (ST_City, ST_State, and ST_Zip) which we won’t go into here. We’ll populate the ST_Address with the two pieces that Weather Underground requires, city and state, and then publish this type to the docker container:
http://192.168.99.100:5001/publishSemanticType? semanticTypeName=ST_Address&instanceJson= { "City": {"City":"Hudson"}, "State": {"State":"NY"} }
The microservice, in HOPE terminology, is a “receptor” that is interested in
the type ST_Address. As implemented in C# (fragment):
public class WeatherForecast : IReceptor
{
public void Process(ISemanticProcessor proc, IMembrane membrane, ST_Address address)
{
string json = Http.Get("http://api.wunderground.com/api/[yourapikey]/forecast/q/" +
address.State.State + "/" +
address.City.City +
".json");
var data = WeatherUnderground.FromJson(json);
var statForecast = data.Forecast.Simpleforecast.Forecastday.Select(d =>
new
{
Month = d.Date.Monthname,
Day = d.Date.Day,
Weekday = d.Date.Weekday,
High = d.High.Fahrenheit,
Low = d.Low.Fahrenheit,
Conditions = d.Conditions,
IconUrl = d.IconUrl,
MaxWind = d.Maxwind.Mph,
}).ToList();
// ...
// Building the day and night detail forecast is not shown.
// ...
Response result = new Response()
{
HopeResultWrapper = new WeatherResult()
{
StatForecast = statForecast,
DayForecast = daySummaryForecast,
NightForecast = nightSummaryForecast,
}
};
// Call back to the host with the result.
RestCall.Post("http://192.168.0.2/hope/result", result);
}
}
The response is associated with an XML file that determines the rendering.
Here’s a fragment showing just the first to rows (the day and the icon) of
rendering definition:

HOPE renders this into HTML and sends the HTML over an HTML5 websocket to the browser where the page defines this tag:

and on receiving the message from host, executes this Javascript:
ws.onmessage = function (wsevt)
{
var msg = wsevt.data;
$("#appContent").empty();
$("#appContent").append(msg);
};
The result is rendered on the browser like this:

By changing the rendering to a VerticalGrid we instead get:

By changing the rendering XML definition again (not shown, it’s quite long) we can show the results from all three collections — stat, day, and night — to render a more detailed forecast.

Of course, in real life, you’ll want to render the results of many microservices. We’ll look at how that works soon!

The above diagram is a high level view of what I’ve implemented with .NET Core 2.0 and Docker. The idea is to take the work I’ve done with semantic types and allow users to create public or private repos of semantic types and microservices that operate on those types whenever they are “published” in the user’s environment.
With .NET Core 2.0, all the core pieces that I need (reflection, NewtonsoftJson, HttpListener, to name a few) are all fully usable with C# 7. And while I’ll eventually return to supporting Python, it is a pleasure work with this concept in a strongly-typed language, as that’s a really key component to semantic processing (yes, of course it can be done in a dynamically-typed language with Python as well, as I’ve demonstrated in previous posts and an article.)
And the beauty of doing this with .NET Core is that it can run in a Linux container, which is so much faster than using Docker for Windows!
I’ll be posting more about the implementation details and writing some articles on Code Project on the subject.

Over the last several months I’ve been working on implementing the Kademlia P2P DHT in C#, as per the specification here. This is a very complete implementation with a couple demos. SyncFusion will be publishing an e-book that I wrote documenting the implementation, hopefully it’ll be out in December.
Now that the eBook has been published by SyncFusion, the source code can be found here.
Can we use just the native .NET classes for developing code, rather than immediately writing an application specific class that often is little more than a container? Can we do this using aliases, a fluent style, and extension methods? If we’re going to just use .NET classes, we’re going to end up using generic dictionaries, tuples, and lists, which gets unwieldy very quickly. We can alias these types with using statements, but this means copying these using statements into every .cs file where we want to use the alias. A fluent (“dot-style”) notation reduces code lines by representing code in a “workflow-style” notation. In C#, if we don’t write classes with member methods, then we have to implement behaviors as extensions methods. Using aliases improves semantic readability at one level at the cost of confusing generic type nesting in the alias definition. Extension methods can be taken too far, resulting in two rules: write lower level functions for semantic expressiveness, and avoid nested parens that require the programmer to maintain a mental “stack” of the workflow. In contrast to C#’s using aliases, F# type definitions are not aliases, they are concrete types. New type definitions can be created from existing types. Type definitions can also be used to specify a function’s parameters and return value. The forward pipe operator |> is similar to the fluent “dot” notation in C#, but the value on the left of the |> operator “populates” the last parameter in the function’s parameter list. When functions are written that return something, the last function must be piped to the ignore function, which is slightly awkward. F# type dependencies are based on the order of the files in the project, so a type must be defined before you use it. In C#, creating more complex aliases get messy real fast — this is an experiment, not a recommendation for coding practices! In F#, we don’t need an Action or Func class for passing functions because F# inherently supports type definitions that declare a function’s parameters and return value — in other words, everything in functional programming is actually a function. Tuples are a class in C# but native to functional programming, though C# 6.0 makes using tuples very similar to F#. While C# allows function parameters to be null, in F#, you have to pass in an actual function, even if the function does nothing. F# uses a nominal (“by name”) as opposed to structural inference engine, Giving types semantically meaningful names is very important so that the type inference engine can infer the correct type. In C#, changing the members of class doesn’t affect the class type. Not so with F# (at least with vanilla records) — changing the structure of a record changes the record’s type. Changing the members of a C# class can, among other things, lead to incorrect initialization and usage. Inheritance, particularly in conjunction with mutable fields, can result in behaviors with implicit understanding like “this will never happen” to suddenly break. Extension methods and overloading creates semantic ambiguity. Overloading is actually not supported in F# – functions must have semantically different names, not just different types or parameters lists. Object oriented programming and functional programming both have their pros and cons, with some hopefully concrete discussion presented here.
Full article on Code Project here.

My personal goal with what I present in this article was to achieve the ability to self-host multiple HTTPS websites that, while in the prototype stage, are still usable by others, thus I want an Internet presence for these sites, but without having to pay for hosting and certificates.
Read the full article on Code Project!


